
UniJobs.it e le cose che si imparano
TL;DR: Ho fatto un sito. Sì, un altro. Spiegone dopo lo screenshot.
Premessa
Un po’ di tempo fa tenevo d’occhio le offerte di lavoro in alcune università italiane. Era l’epoca in cui cercavo borse di dottorato e avevo deciso di provare in varie università, ma schiacciare refresh di continuo e cercare di capire cosa era cambiato tra un refresh e l’altro stava diventando oneroso.
Dopo un po’ a schiacciare refresh, mi sono deciso ad usare IFTTT per generare un feed RSS basato sugli albi di ateneo delle università che stavo adocchiando. Il giochino ha funzionato per un po’, ma poi ha smesso e non ho mai capito per quale motivo. A quel punto comunque avevo già ottenuto la mia borsa e quindi non mi pareva il caso di aggiustarlo.
Tempo dopo, mi sono rimesso a tenere d’occhio le offerte. IFTTT poteva essere una buona soluzione ma, avendo un VPS e un po’ di tempo libero, ho deciso di farmi il mio script che, in aggiunta, mi mandava pure le email con gli aggiornamenti, perché nel frattempo Google Reader è morto e io mi sono un po’ stufato degli RSS [1]. Lo script funzionava abbastanza bene, anche se l’output era un po’ confuso. Non che con IFTTT sarebbe stato meglio, ma gli anni passano, gli occhi si incrociano, e anche dover scorrere una lista di frasi sconnesse in pseudo-burocratese diventa difficile.
A quel punto mi sono detto: potrei migliorare lo script, estrarre un po’ di metadati in più, rendermi la vita un po’ più facile. Poi mi sono aggiunto: questa cosa è utile e vedrai che, se è utile per me, lo è anche per qualcun altro. Nel frattempo avevo ottenuto il mio dottorato e avevo fatto un po’ di domande di lavoro, in università e fuori dall’università, in Italia, in Germania, e nel Regno Unito. In quest’ultimo avevo poi trovato lavoro.
Il modo in cui ho trovato lavoro è stato via jobs.ac.uk, che è un raccoglitore di offerte di lavoro nelle università del Regno. Le offerte sono esposte in modo chiaro, in inglese comune, con gli elementi chiave in bella vista, una descrizione del ruolo, del progetto, e del candidato ideale, e istruzioni semplici per presentare domanda. Il sito attrae visitatori da ogni parte del globo terracqueo, e presumibilmente molti di questi si traducono in domande presentate, col risultato di un pool di candidati di invidiabile ricchezza.
A quel punto ho pensato: vedi mai che qualcosa del genere esiste anche in Italia? Vedi mai che ho fatto tanta fatica con lo script, e poi c’era una soluzione già pronta? Come in molti altri casi in cui la variabile nazionale è l’Italia, la risposta è: nei tuoi sogni più proibiti. E quindi, siccome ho un sacco di tempo libero (…), mi sono detto: perché non farlo? Non potrà mica essere più difficile del famoso script che mi era così utile, no?
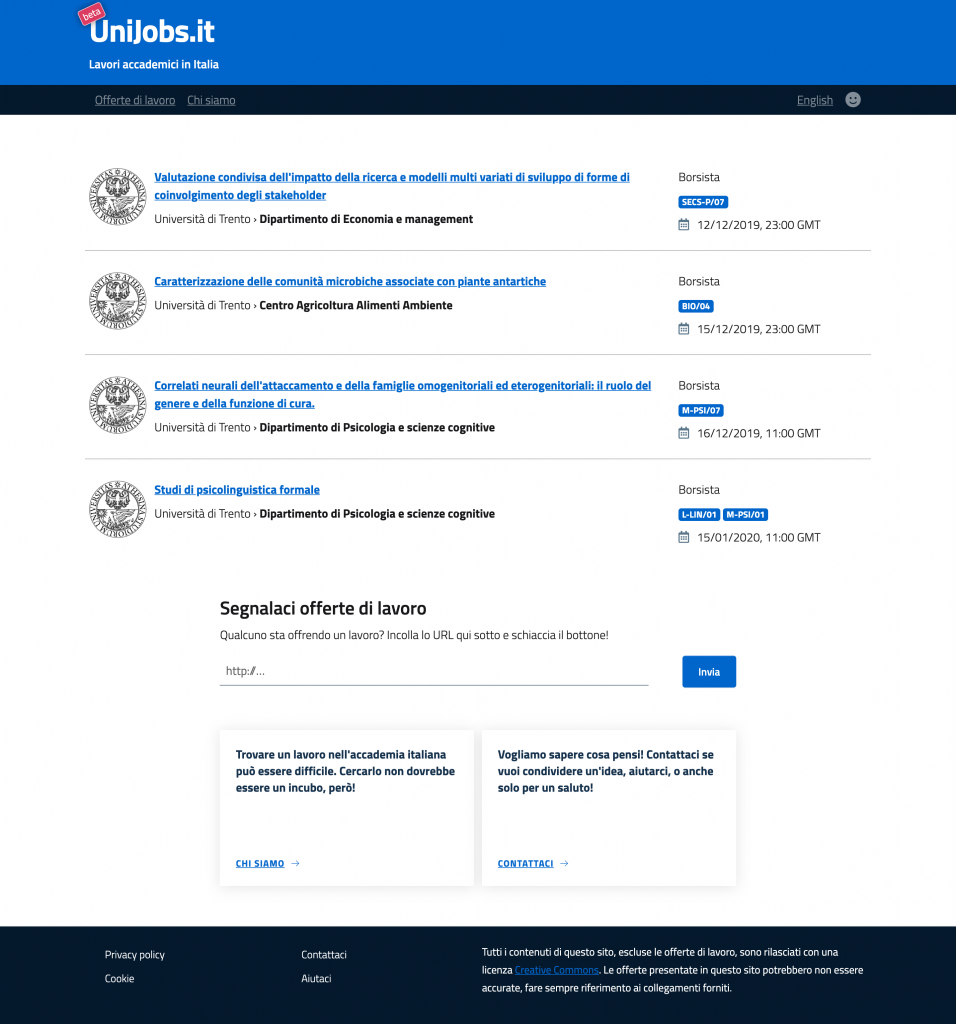
UniJobs.it
Il sito è stato facile. Grazie al mio attuale lavoro, ho imparato come si fanno i siti moderni – spoiler: no, non con Drupal, anche se… – e quindi tirare insieme l’infrastruttura web è stato facile. Ancora meglio è stato avere il design sviluppato dall’Agenzia per l’Italia Digitale (grazie Monti) così da non aver dovuto reinventare l’ennesima ruota [2].
I requisiti sono pochi ma chiari:
- Il sito deve essere liberamente accessibile a tutti, italiani e stranieri;
- Le offerte devono essere presentate in modo chiaro e semplice, in italiano e in inglese;
- Inserire le offerte deve gravare zero, o poco più, sugli uffici del personale:
- idealmente, le offerte vengono inserite meccanicamente;
- dove un processo meccanico non esiste, un editor per l’inserimento manuale facile da usare deve essere a disposizione.
Siccome non sono (del tutto) un povero illuso, sapevo che non avrei potuto contare su alcun aiuto da parte degli uffici del personale. Il compromesso è stato modificare il mio script originale per estrarre quante più informazioni possibili in modo da minimizzare l’intervento manuale prima della pubblicazione. E qui iniziano i dolori.
Data mining
Non avrei mai immaginato in vita mia di dovermi occupare di data mining.
Il data mining (…) è l’insieme di tecniche e metodologie che hanno per oggetto l’estrazione di informazioni utili da grandi quantità di dati (es. database, datawarehouse ecc…), attraverso metodi automatici o semi-automatici (es. machine learning).
Fonte: https://it.wikipedia.org/wiki/Data_mining
Ho cominciato da quello che già conoscevo: l’Università di Padova. L’Albo Ufficiale di Ateneo è una tabellona gigante che contiene una ragionevole quantità di informazioni. Filtrando opportunamente, è possibile isolare i bandi di concorso e determinarne il titolo, la scadenza, e a volte perfino il dipartimento. Oltre a questo – che, ammettiamolo, non è tantissimo – viene incluso un link al bando completo. Questo è normalmente un PDF che, quando va bene, contiene svariate pagine di testo selezionabile, e quando va male invece è una fila di scansioni a cui nessuno si è nemmeno degnato di fare l’OCR. La maggior parte del testo include:
- intestazioni e piè di pagina, su ogni pagina;
- VISTO il decreto tale e talaltro – minimo una pagina, a volte di più;
- almeno un paragrafo in cui si stabilisce l’oggetto del bando ma che sembra più rumore su una linea telefonica, sia per come è scritto che per la quantità di informazione che effettivamente contiene;
- alcune brevi nozioni sulla durata del contratto e sulla misera somma lorda;
- una descrizione del lavoro da svolgere – se va bene, la descrizione è abbastanza completa ed articolata, ma nella maggioranza dei casi è un copia-incolla del titolo del bando;
- requisiti di ammissione, normalmente in termini di articoli di legge che descrivono il tipo di laurea da possedere, e la rassicurazione che titoli conseguiti all’estero saranno valutati equivalenti dalla commissione esaminatrice, ma senza specificare alcun dettaglio;
- altri requisiti di ammissione, per esempio le varie competenze richieste al candidato – da cui non manca quasi mai “conoscenza del pacchetto Office” o “ottima conoscenza della lingua inglese”;
- chi non può partecipare – spoiler: se avete un cugino che lavora nel dipartimento, sognatevelo. Il lavoro, non il cugino.
- come inviare la domanda – normalmente a mano in segreteria, via raccomandata, o via PEC, tre tecniche del tutto a disposizione di uno che vive in Australia;
- e poi boh, di solito smetto di leggere al punto 8.
Per farla breve, lo script passa in rassegna l’albo, scarica i PDF relativi alle offerte di lavoro per varie posizioni accademiche (borsista, ricercatore junior, senior, professore associato, e ordinario), cerca di estrarre il testo – via pdftotext o via tesseract – e poi cerca di estrarre quante più informazioni extra possibili, tipo importo della borsa, settori di concorso, e via così. Infine, schiaffa tutto, incluso il testo del bando per intero, in un CouchDB da cui l’editor dei contenuti importa e prepara il contenuto per gli ultimi tocchi manuali prima dell’inserimento finale.
Gli ultimi tocchi finali includono: estrarre le informazioni utili dal testo del bando tipo chi dovrà fare cosa, quanto a lungo, e perché, e tradurre il tutto in inglese via Google Translate che ovviamente traduce “laurea specialistica/magistrale, o vecchio ordinamento” in “specialist/magisterial degree, or old system”, e tanti auguri. In buona sostanza, il summenzionato PDF viene tradotto in una forma fruibile da esseri umani di medie capacità e in possesso dei requisiti fondamentali. Ora che ci ho preso un po’ la mano, inserire un bando mi prende circa un minuto, ma quando lo script ti estrae venti offerte e tu hai altro da fare, il giorno dopo magari te ne ha estratte altre cinque, e quello dopo ancora… insomma, i bandi si accumulano e perfino io – sembra strano, lo so – ho una vita. Senza contare il lavoro.
E senza contare l’Università di Trento che sì mette le traduzioni dei bandi, ma su due colonne, con buona pace di pdftotext e tesseract che ci provano, poveretti, ma anche loro hanno dei limiti.
La situazione
La situazione è che due università sono difficili da seguire per una persona sola, e non ho avuto alcun tipo di riscontro da parte di chi ho contattato – sia uffici personali che associazioni di studenti e ricercatori. E se due università sono già un casino, figuriamoci un centinaio.
A questo punto potrei anche fermarmi e tornare a casa avendo imparato qualcosa, ma Google Analytics ha una storia da raccontare:
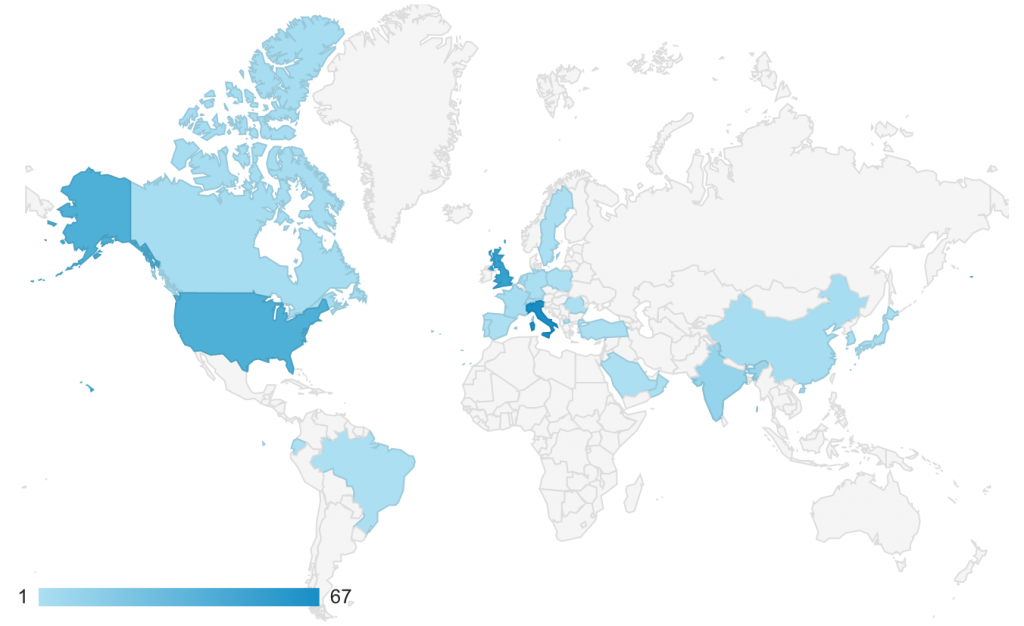
Non tantissimi, ma meglio che niente.
E anche l’account Twitter ha ricevuto qualche cuore e qualche retweet. Quindi per me è chiaro che il giocattolo è utile.
Lo script ha ampio margine di miglioramento. Una cosa che vorrei provare è inserire un po’ di machine learning per estrarre le parti rilevanti dal rumore di ciascun bando. Gli esempi da cui imparare ci sono: ho mantenuto un archivio delle centinaia di bandi che ho inserito semi-manualmente da settembre a dicembre 2019. Non è un compito facile, ma ci sono tecniche promettenti, solo che io non ci capisco molto, e capirci richiede tempo.
È evidente che alcune università usano sistemi automatici per pubblicare i bandi sui loro siti. Sarebbe molto bello se integrassero UniJobs.it nei loro sistemi – l’API c’è, basta usarla. Se invece avessero uno stagista che fa tutto a mano, basterebbe prendere un altro stagista e insegnare loro ad usare l’editor. Giuro che, una volta presa dimestichezza col processo, si fa un bando al minuto.
Insomma
Io sono in partenza per le vacanze, e non avrò tempo di tornarci su prima di gennaio.
Ci sono svariate altre cose che ho imparato, tra cui che lo stipendio medio, tra borse di un mese e assegni fino a tre anni, è di 17079.79 euro. O che ci sono persone che tengono ai loro bandi e scrivono descrizioni dettagliate, mentre altri forniscono a mala pena un titolo – immagino che il motivo sia che tanto le domande arrivano lo stesso, che non è un buon motivo per niente, né una buona indicazione dello stato delle cose. O che il nepotismo non si combatte con le leggi ma col cambio di mentalità.
Ma tutte queste sono considerazioni per la prossima volta. Nel frattempo, se tra i quattro stronzi che leggono questo blog (vi voglio sempre tanto bene, lo sapete) c’è qualcuno che ha qualche idea, i commenti sono aperti, e anche l’email.
- Gli RSS sono ad oggi uno strumento fantastico ma non ho tempo di seguire milioni di post al secondo e quindi ho smesso di controllarli tutti. Ciò mi rende triste, devo ammetterlo.[↑]
- C’è chi dice che quella grafica non dovrebbe essere usata per siti non istituzionali, ma non ho trovato alcun parere contrario ufficiale, e di contro è un gran lavoro di standardizzazione e usabilità, quindi perché non usarlo?[↑]